ACX Prediction Contest 2024 Retrospective
Since 100% of readers will have found this blog from the ACX announcement I'm going to assume you're familiar with the yearly prediction contest. I did the 2024 entry with a friend, who writes over at The Dissonance and has written his own retrospective here which I really recommend for lots of juicy statistical analysis of our predictions. I’m going to avoid duplicating all of his analysis and instead focus on what my key takeaways were, as well as digging into particular questions of interest.
It was our first time trying to build somewhat explicit models and be as quantitative as possible (I’d previously entered one ACX contest with a method most accurately described as squinting at a random number generator). Suffice to say we did way better than we were expecting.

The Method
We wanted to minimise correlated failure modes, so we spent the initial research and modelling time working independently and avoiding sharing any significant information except for clarifications about resolution criteria and the like. We wanted to get through this in a weekend, so allocated 7 minutes per question for individual research and 3 minutes for discussion. In practice this almost always ran over slightly, occasionally by a factor of 3.
We recorded our individual predictions in a spreadsheet, then updated them after our discussions. These updated predictions are what we both submitted to Metaculus. We predicted on every question.
My research methodology almost always consisted of attempting to calculate a meaningful base rate, then looking for idiosyncratic effects that could update me away from this. The 2024 contest seemed to have many questions that lent themselves to this kind of quantitative analysis quite well. For example:
Question: Will the WHO declare a global health emergency (PHEIC) in 2024?
Strategy: Pick a representative timeline and sample. In this case it was clearly going up over time, so I weighted more recent years more heavily.
Question: In 2024 will there be any change in the composition of the US Supreme Court?
Strategy: Look up everyone’s age, and US death rates by age. Subtract a bit from each due to wealth then multiply out. Add epsilon for chance of drastic constitutional changes.
Question: Will {Bitcoin | SSE | S&P500} go up over 2024.
Strategy: Pick a representative long timeline and sample years to get a base probability. Update upwards a bit because this whole AI thing might be a big deal.
These tended to be the sorts of questions where I think we were best calibrated, although it can also be quite hard to gain significant leaderboard points on these, as frequently our predictions would come in pretty much on top of the community prediction.

Most of our questions ended up being close to the community prediction, and I estimate that around 50% of my score came from questions where I was a few percentage points off consensus in the direction of resolution. These are probably quite boring to discuss, so I’ll focus on ones where I disagreed with Metaculus.
What went well?
My second highest scoring question was

When we first saw this we both thought we must have accidentally input 1-P instead of P. In reality though, I think this is largely attributable to resolution criteria lawyering. The question sounds like it’s asking if the November datapoint is going to be higher than 11%, when in reality it requires the average across all of Jan-Nov to be higher than 11%. Given LEV sales were at 8.5% at the end of 2023, this would mean hitting around 13.5% by November assuming a linear growth rate, for a nearly 60% YoY increase. The rate ended up being 9.7%, and not even any of the individual months breached 11%, although some did get quite close. Interestingly enough, this is also the question on which I most affected my co-predictor J’s prediction (if you look at the Question Breakdown graph in his post), and second by effect on Brier score.
Another question I feel quite good about is:
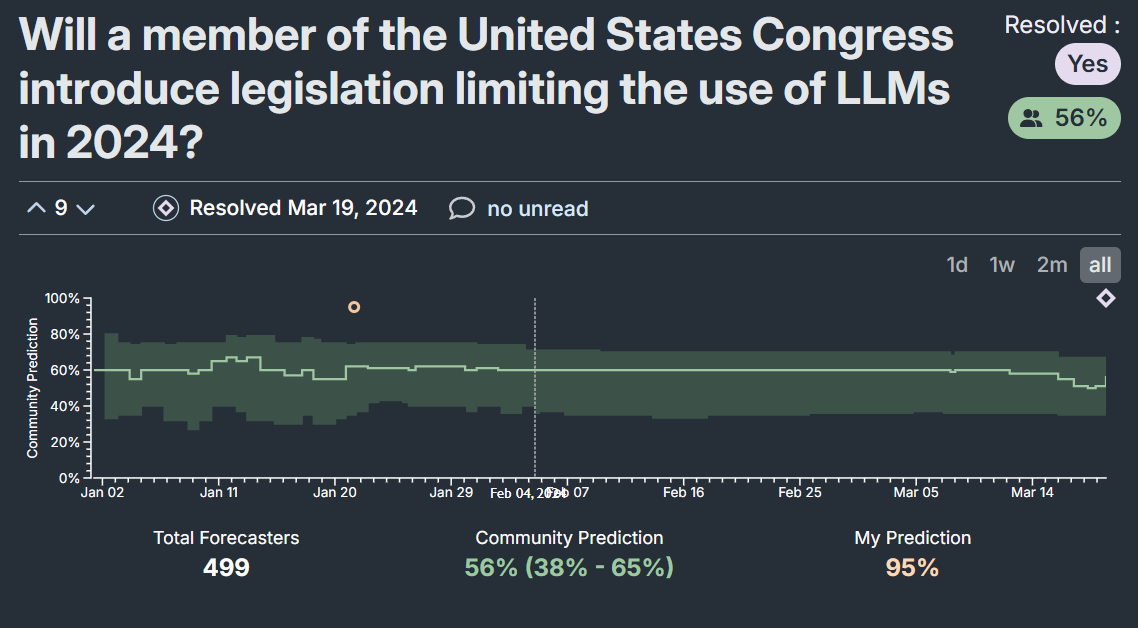
This was actively being talked about by the Biden administration at the time, which had a track record of being somewhat on the ball regarding AI. A large component of my prediction came from this executive order Biden issued, which seemed uncharacteristically detailed and binding. For example, it frequently referred to specific timelines, many of which were 90 or 180 days long.
Within 1 year of the date of this order and consistent with applicable law, the Secretary of Defense, in consultation with the Secretary of Commerce, the Secretary of Energy, the Secretary of Homeland Security, the Director of National Intelligence, and the Assistant to the President for National Security Affairs, shall issue regulations that prescribe heightened safeguards to protect computing hardware acquired, developed, stored, or used on any sites on which frontier AI infrastructure is located and that are managed by the Department of Defense, as needed to implement or build upon the objectives of, or the requirements established pursuant to, subsection 4(g)(iv).
None of it explicitly referenced limitations on AI, but given how popular conversations about copyright were at the time I had high individual probabilities assigned to both some kind of restrictions on training data, and separately on export restrictions on China. I thought the frequent referral to the Department of Defense made the idea of restrictions on foreign countries more likely. Given how soon this resolved, I feel good about my probability.
One more example (my third highest scoring question) was

Since 1950, Israel has had 7 premature prime ministerial resignations (I discount deaths and the one guy who got depressed), for a base rate of 10% per year. I decided to very slightly increase Netanyahu’s chances, since as a rule of thumb support for country leaders increases during times of conflict. My main takeaway is that one should be wary of going too far from base rate, especially since Israel has had many conflicts, so the base rate ought to still be somewhat representative.
What went not so well?
Over 3/4 of my negative points came from two questions, both of which were not amenable to base-rate analysis.
My worst question was

I remember finding it hard to be quantitative about this question, although again I tried to take the number of predicted launches and assigning them an individual probability. I think the downside to this approach is that it can magnify errors in your individual probabilities. For example, with 4 launches, if each has a 60% chance of failure, we get 13% overall, whereas if each has 70% we instead get 24%. This model also completely sucks, because launch failures are likely to be very correlated, so assigning them an individual percentage is pretty meaningless. I think my key takeaway is that putting 90% for a question I don’t especially trust my modelling on is dumb - ie I should probably account for Knightian uncertainty.
My second worst question was

With this one, I remember thinking that it would be a massive publicity nightmare if they didn’t release more information about it. This was patently false, I’ve not heard anyone mention Q* at all recently. I also assumed that this must be the next big thing, based on it leaking, and that therefore the next model release would at least in passing describe Q*.
My main takeaway here is that it’s really hard to model company politics and publicity effects. Also that publicity effects from not doing something are pretty much non existent. How often do you see articles titled “X still hasn’t explained Y”? How long would you wait before publishing this? Who’s the target audience? What else do you say in your article that isn’t in the title?
The Debacle
Given it was our first time participating, we were hoping to come in the top 50%, but not much better than that, so we didn’t think too much of entering a third submission containing our average predictions. This way we could get an interesting comparison of how we did as a team, vs how we did individually, and could get some nice warm fuzzies when our joint account came in the top 30%. We thought about telling Metaculus at the time, but that seemed entirely ridiculous (“Just in case we as complete prediction market first timers do come in the top 5, please be aware…”) so we decided to just leave it.
We checked the leaderboards a few times as the questions started resolving, and were pleasantly surprised to see ourselves slowly notching our ways up to the top 50. Then the leaderboard switched to spot scoring, and suddenly our accounts were 3rd, 4th and 6th.

At this point we reached out to Metaculus, and we agreed that our shared account l1z1x should be deactivated, and that we should forgo our cash prizes. We are very grateful to Metaculus for being so pleasant to deal with about this, for listening to our explanations with an open mind and goodwill, and for allowing us to keep our spots on the leaderboard. For their account of this please see the winners announcement.
On the brighter side, the joint account came 3rd, so it seems wisdom of crowds works despite the saying “two's company, three's a crowd”!
Takeaways
The style of collaboration was great, I am fully committed to independent research time + discussion later.
A lot of the time we came up with similar models, and our updates were relatively small. In this case it might have been worth us collaborating during research, as some effort was duplicated between us.
But sometimes we came up with very different models. When these converged on similar probabilities, this was a strong sign we were onto something. When these disagreed we were usually both able to provide strong arguments that the other had missed, leading to us converging on a more accurate number. There were even times when we both updated in the same direction post discussion - we’d found different data that supported the same prediction!
I think it’s really important that the research is independent. Trying to work collaboratively all the way through is likely to lead to correlated models and errors.
Trust the base rate!
I got a lot of points by trusting the base rate when popular opinion differed from it by quite a lot. I think there’s a human tendency to over-update on recent events. When you see lots of recent news articles complaining about a given prime minister, it’s easy to assume this means a high likelihood they step down. But all PMs have articles complaining about them all the time! This feels somewhat related to Scott’s post Against Learning From Dramatic Events.
I didn’t think of doing this for the 2025 contest, but in 2026 I’m planning to write down my calculated base rate explicitly, and compare that against my final prediction. Subscribe now for more posts in only 644 days time!
Don’t submit joint account predictions on Metaculus
Mike Johnson 4 eva
Our highest probability for any question ended up being “Will Mike Johnson remain Speaker for all of 2024?” at 95%. We thought about this carefully, and I maintain this was a well-calibrated estimate, but it was also a source of endless hilarity whenever Mike Johnson was in the news for anything, and made me way more invested in his speakership than I had any right to be. I also got a very healthy 58 points for this, so I can feel good in hindsight.
More generally, predicting these things made me way more invested in the news than I otherwise would have been. I think this alone is a good reason to participate.